At its core, observability is the ability to truly see and understand what’s happening inside your application. It goes beyond just spotting symptoms—it helps you uncover the root causes of issues, even the ones you didn’t know existed.
It’s common to confuse observability with monitoring, but the two aren’t quite the same.
Monitoring focuses on known problems. You track things like CPU spikes, latency issues, error rates, and warnings. It tells you when something breaks—but only if you knew to watch for it.
Observability, on the other hand, goes much deeper.
It helps you understand the behavior of your application, giving you visibility into areas you may not even think to monitor. It lets you spot unexpected issues, unknown failure modes, and subtle patterns that hint at deeper problems.
Most importantly, it allows you to answer why something is going wrong, not just what is going wrong—often in parts of the system you wouldn’t normally inspect.
This level of insight comes from the three core types of telemetry data, often referred to as the three pillars of observability:
Logs
Traces
Metrics
When you correlate all three, you get a complete, high-resolution picture of what’s happening under the hood of your application. Observability isn’t just about alerting you—it’s about empowering you to understand and fix what matters.
Today I think there are very few people in the software development world who have not heard of the term “microservices” … I see microservices mentioned almost on a daily basis, in discussions, articles, resumes etc… yet (unfortunately), not many people really understand or grasp the true concept behind microservices, let alone be able to design microservices based architecture.
This short article is my humble attempt to provide a quick, high-level overview of microservices and help demystify some of the misconceptions.
What is a microservice?
There are multiple definitions out there on what a microservice is, some talk about breaking down your application into multiple smaller functions, each with a single responsibility, while others talk about creating separate databases or 2 pizza teams, while they are right in their own perspectives and specific contexts, here is my simple, generic definition of a microservice.
Definition: A microservice is an autonomous service, modeled around a single business capability that can be deployed independently.
I know that’s a mouthful, but please note the underlined keywords in the definition above.
Autonomous: For a service to be called a microservice it should be autonomous, meaning, it should be able to stand on its own, function independently and be able to provide its (business) service even when other services are down / unavailable.
Single capability: A microservice should cater to a single capability, and not span across multiple business capabilities, otherwise it would become difficult to make changes to one without affecting others.
Business Capability: A microservice should cater to a business capability, else it would be no different than a helper function.
Deployed independently: You should be able to deploy your microservice independently, without requiring other services to make changes. Since each microservices is autonomous and aligned to a single business capability, it should not be a problem to deploy independently (if designed properly).
What is a microservices architecture?
Now that we understood what a microservice is, let’s try and understand what a “microservices architecture” is… to put it simply, a microservices architecture is a style of distributed architecture where the application is an aggregation of individual microservices, supported by infrastructure services.
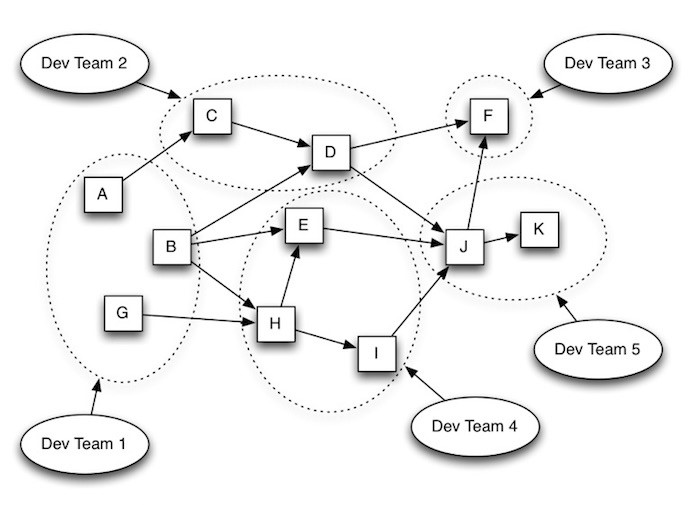
As you can see from the diagram below, the square boxes (A, B, C, D, etc.) represent the individual microservices that work with each other to form an application. Also as you can see from the diagram, these microservices can be developed and maintained by separate teams with different skillsets, each team responsible for one or more microservices based on their team size, domain knowledge and technical expertise.
(Image Source: Unknown)
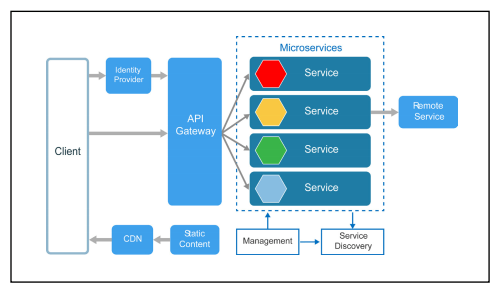
Microservices are generally supported by helper functions and infrastructure services that take care of cross cutting concerns (like authentication, caching, logging, application monitoring, api gateways, service discovery etc.). This helps microservices to remain lean and focus on the business logic and delegate non-functional aspects to other supporting services.
(Image Source: Microsoft documentation)
Characteristics of a well-designed microservice
Now that we understood a little bit about microservices and its architecture, let’s look at some of the characteristics of a well-designed microservice.
Autonomous, single business capability and deployed independently – we already discussed this in the above sections.
Owns and manages data (source of truth) for the business capability – since each microservice caters to a particular business function / capability, and has the most knowledge pertaining to that service, it makes a lot of sense for it (and the team behind it) to own the data and be the source of truth for that business function. Its ok for other services and materialized views to keep copies of the data for various purposes, but the microservice that owns the business capability should be the custodian and the authoritative source for the data in case of conflicts / mismatch. This also requires that each microservice maintains its own independent data store / table / blob storage (or an event store in case of event-sourced systems).
Does not share / expose the data store (database) with other services – this is one of the best things you could do and thank yourself in the long run. A lot of you probably are a witness to this problem in your own workplace, where you don’t even know how many applications or services are directly connecting to your database… and even if you know, you can’t make any changes to your database because it might break those applications that you don’t have a control over. The best practice is to not allow other applications / services to directly connect to your data store. The next point talks about how to do this the right way.
Exposes APIs and hides raw data and implementation details – your APIs should act as your contract and documentation to your consumers. Always define well thought out APIs and let other services talk to your microservices through those APIs so that you have better control over your data and implementation. Well thought out APIs rarely go through change, except when you need to enhance or add new functionalities, and when they do change, you should create a new version of the API and maintain the old version in parallel until all your consumers have migrated to the new version. This abstracts the implementation details from the API and allows you to freely make internal changes to your data, schema, business logic or business rules without affecting other services.
Designed with failure in mind – resiliency is built into every aspect of a well-designed microservice so that it is prepared to handle failures, whether it’s the network, hardware or other application or infrastructure level failures. There are many well-established design patterns that can be implemented within the microservice to help achieve resiliency such as the circuit breaker pattern, bulkhead, compensating transactions, health check endpoint, leader election patterns, etc.
Supported by infrastructure services – as mentioned earlier a well-designed microservices architecture will delegate cross cutting concerns like logging, AuthN/AuthZ, monitoring to other supporting services so that the microservices themselves are lean and focused on the business logic and does not have to do any of the heavy-lifting when it comes to cross cutting concerns.
Smart endpoints and dumb pipes – This refers to the type of communication used by microservices to interact with each other. There are mainly two types of communication styles:
Decentralized or choreography based approach (aka the “pull model” or “smart endpoints and dumb pipes”) where there is no centralized decision maker, no intelligent workflow service that makes routing decisions or decides the call sequence, there is only a simple messaging system (dumb pipes) used to deliver messages between smart endpoints (microservices). Each microservice informs the messaging system what events they are interested in receiving, and what events they will generate for others to consume, so that the messaging system can do the routing. This style of communication is better suited for scalability and extensibility as things are loosely coupled.
Orchestration based approach (push model):In this style, there is a centralized workflow that contains the routing logic, decision logic and controls the call sequences. While this approach may be right in certain scenarios, this also creates tight-coupling between the orchestrating service and the microservices.
Has an independent codebase, repository, and DevSecOps automation (CI/CD tooling) – each microservice should have a separate codebase, including all its libraries, tracked by version control system and a separate instance of build and release infrastructure (pipelines, static code analysis tools, unit testing, build & deploy scripts etc.). This will allow you to manage the source code (check-in/check-out, branch, merge, pull, commit, etc.) independent of other codebases and will allow you to release your service to production without depending on other codebases.
What is NOT a microservice?
Ok, now that we have a fair understanding of what a microservice is, let us look at it from a different perspective by understanding what is NOT a microservice.
Simply having serverless functions with REST APIs is not microservice if it does not conform to our definition of a microservices.
Simply using Kubernetes and running apps inside docker containers does not make it a microservices architecture, because technically you could also run monolithic apps inside a container.
Horizontally slicing your apps into UI Service, business logic service and data service is not breaking it down into microservices, because they are not broken down by business capability.
Simply using an event-driven architecture does not make it a microservices architecture, because you could do that between monolithic applications.
Simply using a microservices framework like Spring Boot, Microdot, GoMicro, Moleculer (NodeJS) does not automatically convert your apps into microservices.
Advantages of using (or when to use) microservices
Improved Productivity – it’s much faster for the dev team to build, test and deploy a small service than to build an entire application, it’s also easier to comprehend the functionality when the scope is small and well-defined. Having a small codebase also makes it easy to maintain and refactor the service continuously for better quality, stability, and performance. If your application is large and complex and your team is finding it difficult to manage and comprehend the application as a whole, and not able to move fast on new releases or experiencing quality / reliability issues, then it’s worth looking into microservices based architecture to see if it helps improve productivity by breaking down your monolithic application into smaller services based on business capability.
Better resiliency – Microservices architecture provides better overall resiliency since it does not bring down the entire application when something goes down. Also, as mentioned earlier it is much easier to implement resiliency design patterns on a smaller scope than at an application level. It is also easy to troubleshoot issues, find the root cause, fix it, and redeploy the service. If you see that your application is going down all the time for one reason or the other, then maybe it’s worth looking into the advantages of breaking down the applications into smaller, more manageable, autonomous services, so that failures are isolated and does not bring down the entire application.
Polyglot programming – Microservices architecture allows you to choose the right programming language for the functionality being developed while still allowing interaction with other services written in different languages. This also allows you to leverage existing resources and skillsets. For example, if you have a team of data scientists proficient in python and R programming and wants to develop an artificial intelligence (AI) or statistical computing service, then you could allow that service to be developed in python / R while rest of the application is written in C#/Java/Go/Node.js. Microservices architecture not just allows you to mix and match programming languages, it also allows you to choose the right infrastructure services and databases (SQL/No-SQL/Graph/Timeseries) best suited for the specific capability being built.
Constantly evolving application – Microservices architecture allows you to continuously evolve your services, whether adding new features or modernizing parts of your application. If your application is constantly evolving, causing frequent disruptions, then it is worth considering breaking your application into smaller chunks, grouped by business capabilities, so that you can test and deploy only the changed services, which is much faster and less error prone than testing and deploying the entire application.
Better and selective scaling – Microservices architecture allows you to selectively scale only the required services. If you need to scale out certain business capabilities dynamically based on load, peak hours or seasons… then breaking down your application into microservices might be a good idea. For example, if you are into restaurant business and you know that your order intake module gets a huge amount of traffic between 11AM and 2PM, you can quickly scale out just the Order microservice and automatically scale it back once the peak is over. Scaling out the entire monolithic application just for the Order service might not be quick enough and/or might consume more resources.
Ability to quickly react to market changes – Microservices architecture allows you to make frequent changes to your application with minimal impact. If you are in a highly competitive business and you need to quickly react to market changes / regulations, then your time to market would be much faster if your application was broken down into individual business capabilities so that you could make changes only to the right service, test and deploy it instead of having to test and deploy the entire application taking more time and effort.
Better ownership of data – As mentioned earlier, each microservice encompasses a single (or parts of a) business capability and owns its data. This allows data to stand on its own and contain everything it needs to be meaningful with respect to the business capability. This also allows the data to be separated into smaller manageable chunks making it easier for the team to own, manage and maintain security and integrity of the data and designate it as the “source of truth”. This enables you to choose the right datastore for the type of data (SQL/No-SQL/Graph/Timeseries).
Smaller team size – Since the scope of microservices are usually small and well defined, it allows you to have multiple small teams, organized around business capabilities. Smaller teams also tend to be well-connected, enabling better collaboration within the team and function independently.
Reusable services – Since microservices are standalone autonomous services, they can be used by multiple applications if you design it well. For instance, in the polyglot programming example mentioned above, the AI / statistical service developed by the data scientists could be used by multiple applications / divisions if designed well (generic and loosely coupled).
Challenges (or when NOT to use microservices)
There are some challenges as well when deciding to move to a microservices based architecture:
Has a steep learning curve – Distributed architectures are complex in general, you need to understand the art and science behind defining the scope and boundary of each microservice, how to discover and communicate between services, anticipate all kind of failures related to network, hardware, software etc., and how to persist data that spans multiple databases. So, if your dev team does not have the required skillsets or bandwidth to learn, or the company is not willing to spend money to train the team, hire experienced developers, or make the necessary process changes, then probably this is not the right time to embark on this journey.
You might not get it right the first time – You might need to refactor the services over multiple iterations before you get it right, this takes time and experience, so if you are in a hurry with non-negotiable deadlines and do not have the time for trial and error, it might not be the right time to introduce microservices.
Non-critical reads might be “eventually consistent” – In a microservices architecture, you might need to separate out critical and non-critical reads to be able to improve performance and scalability and might have to live with some inconsistent results for non-critical operations. If this is not something you are ok with, or you need time to understand this paradigm shift, or to convince the business stakeholders, then this might not be a good time to introduce microservices architecture.
Hard to manage without automation – Generally in a microservices based architecture, there are a lot of moving parts… each having their own configurations for things like API endpoints, gateways, identity providers, databases, etc., very soon things can become hard to manage, and difficult to keep track of everything. The best way to solve this problem is through automation. You will need to automate the ‘build and deploy’ activities including things like static code analysis, unit testing, vulnerability scanning, release management etc. You will also need to set up Infrastructure as Code (IaC)) using tools like Terraform, Azure CLI, ARM Templates, CloudFormation etc. and manage configuration using Chef, Puppet, Ansible etc. So, if you do not have the required skillsets to set up CI/CD infrastructure nor intend to establish a DevSecOps practice and mature it, then getting into microservices might cause you more harm than good.
This video provides a quick overview of Azure Active Directory from a developer’s standpoint and gives a glimpse of the new identity features in Visual Studio 2015 that make it easy to secure applications with Azure AD.
In May 2011, the Jericho Forum, a forum of The Open Group, published its Identity, Entitlement & Access (IdEA) commandments, which specified 14 design principles that are essential for identity management solutions to assure globally interoperable trusted identities in cyberspace.
These IdEA commandments are aimed at IT architects and designers of both Identity Management and Access Management systems, but the importance of “identity” extends to everyone – eBusiness managers, eCommerce operations, and individual eConsumers.
The Jericho Forum has created a series of five “Identity Key Concepts” videos to explain the key concepts that we should all understand on the topics of identity, entitlement, and access management in cartoon-style plain language.
Video 1: Identity First Principles
This video, entitled “Identity First Principles,” describes fundamental identity management concepts, including core identity, identity attributes, personas, root identity, trust, attribute aggregation and privacy. These can be complex concepts for non-identity experts. However, these videos were produced in an easy-to-understand manner, regardless of your expertise.
Video 2: Operating with Personas
In the second video explains how creating a digital core identifier from your (real-world) core identity must involve a trusted process that is immutable, enduring and unchangeable.
Video 3: Trust And Privacy
The third video explains how trust and persona interact to provide a trusted privacy-enhanced identity ecosystem.
Video 4: Entities and Entitlement
“Entities and Entitlement,” explores the bigger picture of identity management and how the concepts of a core identifier and an identity ecosystem can be expanded to include all entities that require identity in the digital world.
Video 5: Building a Global Identity Ecosystem
Using the concepts addressed in the previous four videos, this fifth and final video of the Identity Management series presented by the Jericho Forum, “Building a Global Identity Ecosystem,” highlights what needs to happen in order build a viable identity ecosystem.
For all those FIM experts out there who have been waiting to get their hands dirty on the new Microsoft Identity Manager (MIM), the wait is finally over. You can download the CTP from the Microsoft Connect website here.
Here is a quick code that you need to include in your relying party’s global.asax file to setup a sliding window session for your federated / claims aware application.
In some cases, you may need to retrieve the context of the RP at the IdP end after passing through the FP.
For example, your IdP may want to know the name of the RP for which the token is being sought (although this may not a good design). In such cases it is possible to retrieve the context of the RP if you are using ADFS as the federation provider.
By default, the ADFS server encodes all the original context information about the relying party within a cookie when redirecting the user to the IdP. However, if you go the web.config file of ADFS and change the following context element to false, you will see now that the url when accessing the IdP contains a huge queryString (about half a page long).
<contexthidden=“true“ />
What has happened is, ADFS instead of putting the original RP context into a cookie has stored it on the URL itself, but the original query sting is nested within another queryString, so if you are using a custom STS as your identity provider, you can use the following code to retrieve the original context.
In most common Identity Federation scenarios, there are multiple external Identity Providers (IdP), but the relying party (RP / claims aware app) depends and trusts only one STS (Security Token Service) to provide the claims.
This STS is known as the Federation Provider (FP) or R-STS (Relying Party STS). So when you access the relying party application, it will redirect you to the R-STS (the only STS it knows) to get authenticated, now since (typically) R-STS / FP is not an Identity Provider (IdP), it will (typically) provide you a list of trusted identity providers so that you can choose the one you wanted to get authenticated with.
But in some cases, especially if you are using the application frequently and you know which IdP you wanted to get authenticated with, you would like to avoid that annoying extra step / screen where you need to choose the IdP and wish the system knew it instead of asking every time.
Well there are multiple ways of achieving the same, below are some of the options:
1.The (default) cookie based approach
The default behaviour is that, the first time you select the Identity Provider and get successfully authenticated, a persistent cookie is created that is valid for 30 days. This means you don’t need to worry about selecting the identity provider for the next 30 days, however this can have the following issues:
a.Every time you clean up / clear the cookies, you will need to set it up again
b.If you want to change to another Identity Provider, you will need to clear the cookies or for temporary purposes use an “In Private” browser session
This default behaviour can be modified, in ADFS’s web.config located (default) at C:inetpubadfsls
You can either modify the lifetime of the cookie or make it a non-persistent cookie in which case, it will ask you for home realm discovery on every new browser session (not what we want)
2.Using the WHR parameter within the queryString / URL
Another approach is to use the WHR parameter in the URL / queryString when accessing the relying party as shown below:
ADFS by default understands the WHR parameter, however, you need a paste a little code in your global.asax of the relying party for WIF to go the magic. Here is the code that will do the trick:
What you are doing here is basically hooking up your code to the event WIF raises just before it calls out / redirects to the FP. In the code snippet above you are checking to see if the URL contains a querystring with a WHR parameter, if so you assign the value of that parameter to the HomeRealm property of the SignInRequestMessage.
3.Hardcode the IdP’s endpoint within RP’s web.config
I would like mention here that the last two approaches we saw are useful for the end-user or the client browser to customise the behaviour, where each end user might want to choose a different identity provider for the same relying party. However, if you have a scenario where the users of your relying party can be authenticated by a particular identity provider, then you may have to resort to the technique mentioned in this section.
You might ask…, “…well, if the RP can be authenticated by one identity provider only, then why are we even providing a HRD page and choice of multiple Identity Provider?…”. Well you should be conscious of the fact that in a real production environment the Federation Provider may not be dedicated to your relying party alone, maybe it is an Org-wide FP and multiple RPs are using it to federate with various identity providers, but your scenario might demands that the FP redirects the user to a particular IdP only and not provide an option to choose from.
You can configure your relying party to automatically pass through the FP and get redirected to the designated IdP by assigning the IdP endpoint using the HomeRealm attribute of the <wsFederation> node in the <federationConfiguration> of the web.config as shown below:
Finally (for ultimate flexibility) you can modify the HomeRealmDiscovery.aspx file and the associated HomeRealmDiscovery.aspx.cs file and provide your own custom logic.
Or you can leave them intact as is, and provide your own custom HRD page and point to it from the ADFS web.config by modifying the element shown below.



Written
on 6-Jan-2015